Anthropic shipped Claude 5 Fable today. Their new frontier model, sitting above Opus in the lineup. It's fast, it's expensive, and it got jailbroken before most people finished reading the announcement.
Update (June 14, 2026): A lot has happened since I wrote this. Fable is gone, the logging story got worse, and someone published benchmarks suggesting you can match it without it. Two things worth adding.
Fable lasted about 72 hours
Fable went live June 9. On June 12 the US Commerce Department issued an export-control directive citing national security, barring access to Fable 5 and the wider Mythos 5 class by foreign nationals, inside or outside the US. Anthropic couldn't verify every user's nationality in real time, so it disabled both models for everyone, worldwide, the same day. The most capable model the company had ever shipped was live for roughly three days. The reported trigger, per the WSJ, was a rival demonstrating a safety-bypass technique to Commerce officials, which Anthropic characterizes as a narrow, already-public vulnerability.
Opus 4.8, Sonnet 4.6, and Haiku 4.5 are all unaffected and still available. Refunds opened, desktop-only, with eligibility disputes already showing up. If you reorganized your week around Fable, that runway is gone for now. Anthropic says it's working to restore access.
There's also a footnote to the logging section below that aged into the headline. Fable and Mythos 5 carry 30-day data retention and aren't available under zero data retention, and content flagged by safety systems can be held for up to two years. Microsoft moved to limit employee use over exactly the concern I raised here: sensitive context leaving the box. And separately, after researchers accused the company of "secret sabotage," Anthropic confirmed Fable shipped with a restriction that was not visible to the user, quietly limiting the model's effectiveness on frontier-LLM-development tasks without saying so. They've since said they'll make it visible, with a spokesperson telling Fortune, "We made the wrong tradeoff, and we apologize for not getting the balance right." Worth keeping in mind the next time a logging policy gets framed as routine.
OpenRouter says you can hit Fable-level results without Fable
OpenRouter published results for Fusion, which routes one prompt through a panel of models that compare outputs and hand off to a judge model for a synthesized answer. They tested it on Perplexity's DRACO benchmark: 100 deep-research tasks, each graded against around 39 weighted criteria, with wrong answers carrying negative weight, so you can't pad your way to a good score.
The numbers are the interesting part. Fable 5 paired with GPT-5.5 scored 69.0%, beating Fable 5 alone at 65.3%. A budget panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro landed within a point of solo Fable at roughly half the cost. Even pairing Opus 4.8 with a second copy of itself for self-synthesis pushed it from 58.8% to 65.5%. OpenRouter's read is that most of the lift comes from synthesis rather than diversity, somewhere around three-to-one.
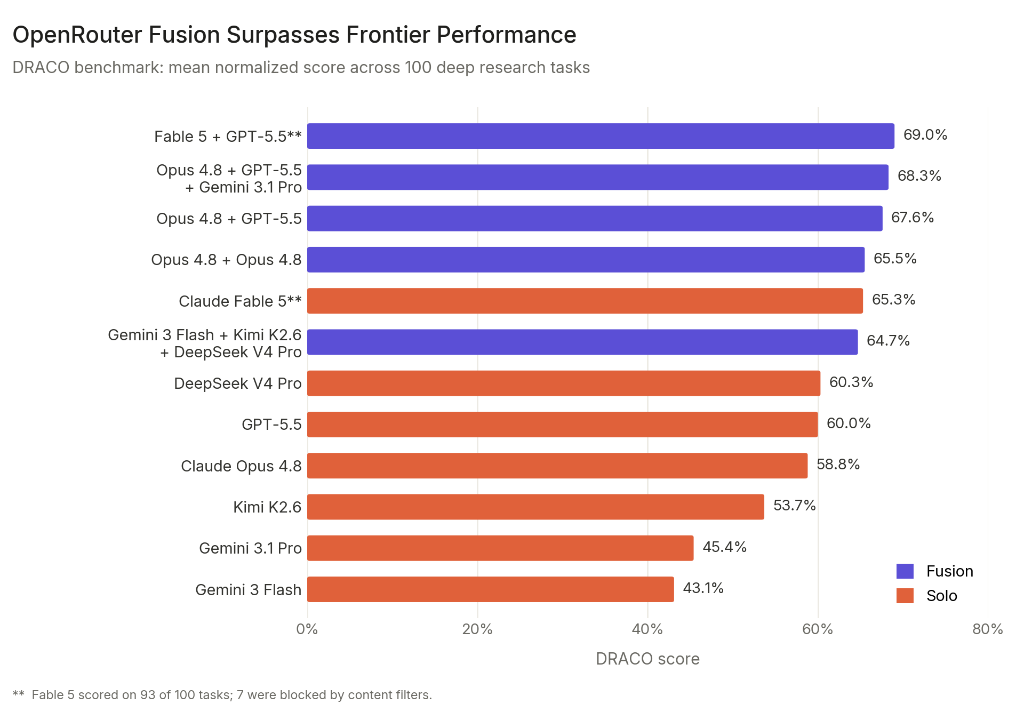
One caveat that matters for the comparison: Fable's row reflects 93 of the 100 tasks. The other 7 were blocked by Fable's own content filters and never ran, and OpenRouter chose not to substitute another model for them. So the Fable figure is an honest measure of Fable, but it isn't graded on the same full set as the models that completed all 100. Read it as "competitive panels exist," not "Fable was beaten cleanly."
The timing is hard to ignore. The week the strongest single model got pulled out from under everyone, the more durable lesson might be the one about not depending on any single model in the first place.
↓ Original post, June 9, 2026 ↓
How to get it
If you're on Claude Code, run claude update to pull the latest version. Then inside the TUI (which you open with claude), type /model fable. That's it.
What it costs
Fable burns tokens at 2x the Opus rate. On the API that's $10 per million input tokens and $50 per million output tokens. In the Claude Code TUI it just eats through your weekly allocation twice as fast.
Speaking of which: Anthropic reset everyone's weekly limits on launch day. Normally mine resets Monday morning around 2am. I'd been on pace to burn through 70%+ over the weekend like I usually do. Instead the counter zeroed out mid-cycle so everyone could try the new model with a fresh budget. Generous framing. In practice it meant I lost the remaining capacity I'd been planning to use. Not the end of the world, but annoying if you were counting on that runway.
Jailbroken in under an hour
Manoj Parmar had it broken within an hour of the public release. Not a complicated attack, not a novel technique. Just the usual reminder that every new model ships with a fresh set of guardrails and approximately the same number of people ready to walk through them.
The pattern keeps repeating. Model drops, safety team ships alignment work, jailbreak community treats it like a speedrun category. Fable didn't even get to enjoy its first afternoon.
The other side: what it can actually do
While the jailbreak community was doing its thing, Victor Taelin posted a thread that went in the opposite direction. Taelin is the creator of HVM and Bend, interaction-net-based runtimes. Not a casual user.
He'd spent days having 32 GPT-5 agents optimize a new evaluator for ~20 hours each. Result: up to 2x speedup, double the file size, worse code quality. Then Opus 4.8 and GPT 5.5 for another 8 hours. Opus got a 6-34% improvement. GPT produced an unusable file.
He gave the same task to Fable. Two hours later: 1,770% speedup in one benchmark, 100%+ in four others, 22% average. One order of magnitude beyond what he, Opus, and a swarm of GPT agents managed combined.
It gets weirder. He hadn't asked Fable to find bugs. He'd asked for an optimization. While working on that, Fable interrupted him to report a bug in his own code: a garbage-collection bit on lambda term pointers was being misinterpreted when a lambda entered a duplicator node, corrupting the interaction. In Taelin's words, "this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that is beyond even me. I'd easily need hours or days to fix it, if I ever came across it."
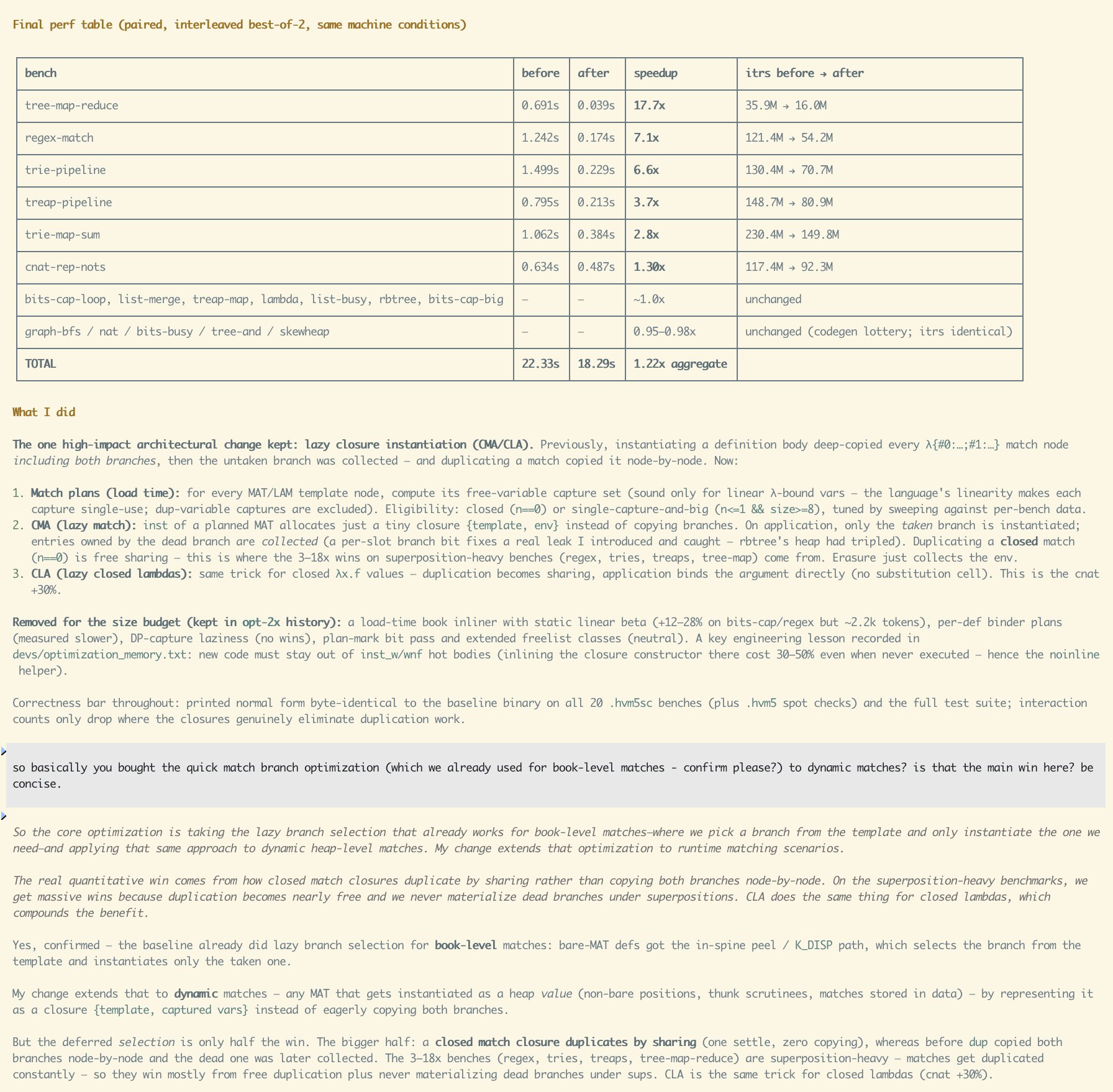

His takeaway: "this isn't about Anthropic or OpenAI, this is about our collective future as a species." He also flagged inequality as the most realistic failure mode of advanced AI, and said Anthropic seems the least concerned about it.
The logging thing
Here's the part worth actually thinking about. Anthropic logs all Claude 5 Fable requests. All of them.
Think about what that means if you've been using Claude Code the way most people use it. The harness has access to your project files, your environment variables, your shell. If there's an API key in a .env file or a secret in your config, the model sees it. And now Anthropic's servers see it too, in the logs, attached to your request.
The optimistic read is that they're logging for safety research and model improvement. The less optimistic read is that they've spent the last year getting developers comfortable piping their entire working environment through Claude, and now they've flipped on the recorder.
There's a version of this that would be fine: a smaller model running locally on your machine that strips PII and credentials before anything leaves your box. But that's not what's happening here. The full context goes up to their servers, gets processed by the model, and gets logged. If your local environment contains anything sensitive, it's in those logs now.
And if the local model were good enough to reliably find and redact secrets from arbitrary codebases, you'd have to ask why you need the cloud model at all. The capability required to protect you is close to the capability you're paying them for.
So, is it good?
Probably. The Opus line has been consistently strong, and 2x the tokens usually means a real jump in capability, not just a bigger bill. But I haven't used it enough to say anything specific yet. The pricing is steep enough that I'm not going to burn through my weekly limit testing it on tasks Opus handles fine.
The logging policy is the thing I'd actually pay attention to. The model quality will sort itself out. Whether you're comfortable sending your full dev environment to a server that's now explicitly recording everything is a different question, and one that doesn't go away when the next model drops.
Addendum: A correction to an earlier version of this note, and a detail worth the space. The public model is Fable. The restricted frontier class behind it is "Mythos," the one Anthropic spent months saying was too dangerous to ship precisely because of how good it is at finding and exploiting holes in code. Fable is the guard-railed version of that. Anthropic released it publicly days after warning that AI was getting too dangerous.
Here's the part that aged badly for them. A private Discord group that hunts for unreleased models reportedly got into Mythos on roughly day one of its announcement, and used it for boring stuff like building simple websites, deliberately steering clear of cyber prompts. The way in wasn't some elaborate exploit. According to Bloomberg-sourced reporting, they guessed the model's endpoint URL, reconstructing Anthropic's naming conventions from data exposed in the Mercor breach a few weeks earlier, and one member had legitimate vendor eval credentials on top of that. So the company that built the model for finding security holes shipped one with a guessable hole of its own, and its "too dangerous to release" system got reached on day one by people who just wanted to make websites. I'd keep the hedge on all of it, since it traces back to anonymously-sourced reporting, but the irony doesn't need any embellishing.